
Our recent SEO Statistics which polled over 2,000 respondents showed that over 50% of user traffic on the web is from organic search, even though 90% of content gets no traffic ever. So with visibility on Google and other search engines becoming ever more challenging, there is no better time to make your SEO, data driven.
- What is data driven SEO?
- How is data driven better than best practice SEO?
- How can data science makes SEO more data driven?
- What are the main sources of data for SEO?
- Resources to make SEO more data driven
What is data driven SEO?
Data-driven SEO is an approach to search engine optimization (SEO) that involves using data to inform and guide the optimization process. While SEOs always (should) have been guided by data, as an approach, data driven SEO has been aided by the advances of:
- Machine learning (ML) – (semi) automated statistical models to reliably find patterns in data and better understand SEO
- Cloud computing – facilities such as Google Cloud Platform (GCP), Amazon Web Services (AWS) and Microsoft Azure to store SEO data at scale and run ML models
This approach typically involves using a variety of data sources and tools and analyze the data on factors such as search results (e.g. search intent), website traffic performance, user experience, technical data (content indexation) and conversion rates. As a result SEO experts are in a better position to better:
- understand website’s search engine performance, user behavior, and relative internet popularity
- identify opportunities to refine the SEO strategy and more impactful recommendations
- measure the impact of their efforts, and continuously improve search engine performance over time.
Positioning the website that is more likely to rank higher in the search engine results pages (SERPs) for the appropriate keywords.
Some may mistake data driven SEO as producing data led content to make it more appealing to journalists so that they provide a backlink from their website to the content. That’s not data driven seo but data driven content marketing!
How is data driven better than best practice SEO?
Data-driven SEO is more reliable and therefore better than best practice SEO because it relies on empirical data to make decisions rather than simply following industry best practices which can often be anecdotal.
Anecdotal SEO best practices are risky because they are based on assumptions such as the best practice works across all sectors. Applying these could have negative outcomes for a site’s organic traffic.
For example, it’s considered best practice to write content to be highly readable (i.e. a low Flesch Kincaid Reading age level). However, this is not always the case.
Taking a data driven approach would mean The chart below plots the average Google rank against the Flesch Kincaid Reading Ease of content for the legal sector.
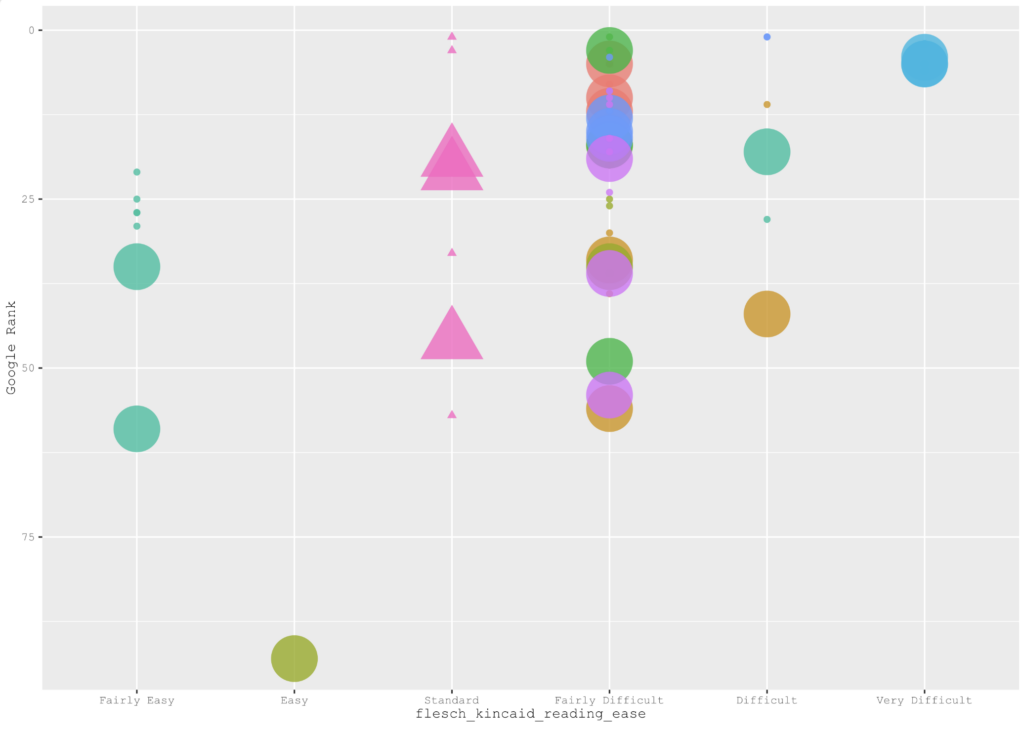
Taking a data driven approach would mean responding to the data shown in the chart rather than blindly following the SEO best practice of creating content that is highly readable.
The data in the chart reveals that for highly technical markets such as law, Google favours content that is highly technical and thus difficult to read, so that the less readable the content is, the higher the Google rank.
The content reading ease is just one example of how anecdotal best practices flies in the face of a data driven approach to SEO.
That’s not to say there’s isn’t a place for best practice SEO as:
- Data sources may not exist or be available to test a SEO hypothesis such as first party data of competitor websites (as useful and desirable it would be!)
- Even with the available data sources, not everything can be split A/B tested
- The search results are dynamic. For example, Google’s Core Updates can often takes days to roll out before stabilizing which may overrun with another Google algorithm update making clinical-level data driven conclusions impossible.
By analysing data a data driven approach can tell us much more and answer questions such as:
- What is the ideal benchmark?
- How many rank positions is this worth in Google?
- What are the most important ranking factors for my site?
- How long will it take before this implementation takes effect in Google’s search results?
Best practices could only hope to answer such questions the way a data driven approach can as we’ll discover next.
How to take a more data driven approach to SEO
Fortunately for the organisations that rely on SEO consultants the world over, data driven SEO is becoming less of a novelty and more standard. Especially as more SEOs are turning to the Python computing language as part of their career development.
Of course, knowing Python is not enough, as it’s merely the expression of the statistical ideas. Data science knowledge is far more important to:
- Understand how the SEO problem could be solved from a data science perspective for hypothesis formulation
- Have ideas on data sources for SEO and non-SEO exploration. The more SEO knowledge you have, the better questions you can ask of the data, create new features and take a critical view towards the quality of it also
- Know the maths to select the right models to find insight from the data and/or split AB testing
- Analyze data using Python data tools such as Pandas, NumPy, and Matplotlib to identify trends, track website performance, and lead to data-driven decisions.
- Automate SEO processes especially the repetitive ones such as updating meta tags, generating XML sitemaps, and performance reporting.
With the principles outlined above, we asked SEOs on LinkedIn what their data driven priority was for SEO, and here’s what we found:
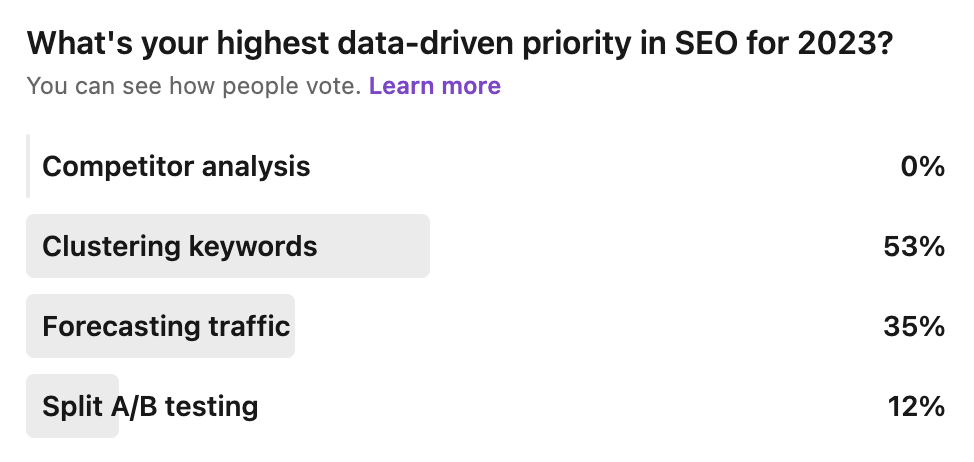
So keyword clustering turned out to be the highest priority for SEOs, which makes sense as it’s highly topical in 2023! Astonishingly, competitor analysis received very few votes.
We’ll now explore just some of the many ways SEO can become more data driven and the techniques involved:
Competitor analysis
The aim of competitor analysis is to understand and quantify the factors that can best explain the variation in rankings between competitors and your own site. Traditionally, SEOs would eyeball data in spreadsheets or analyze the search results.
A more data driven approach would be to understand that Google rank positions are the outcome variable which is continuous (i.e. a number that’s infinitely divisible). This is best modeled by regression analysis (i.e. a unit change in ranking factor results in a proportional change in Google rank).
The ranking factor data could come from a variety of sources from crawling for technical factors to offsite factors such as backlink metrics.
Once the data is cleaned, transformed and formatted it can be fed into a Machine Learning algorithm (hint: decision tree is best for non linear factors like title tag length) to uncover competitive influential ranking factors:
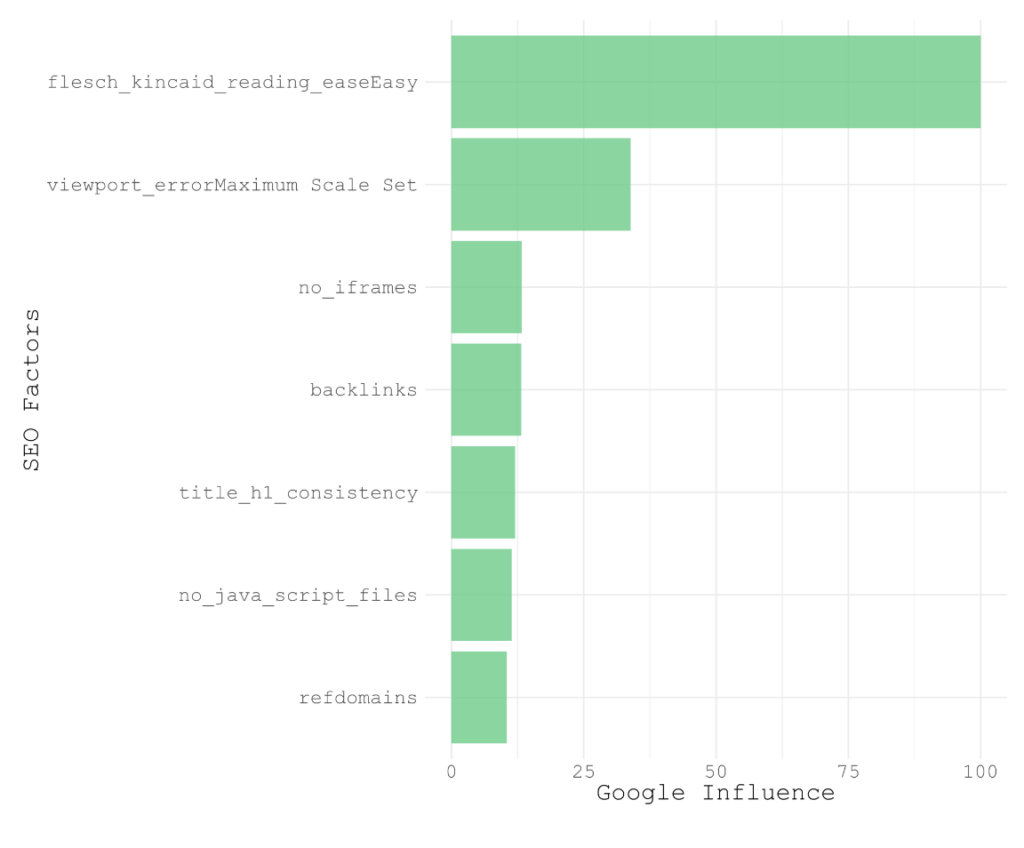
The chart above shows the most influential ranking factors for a london based law firm specializing in commercial law.
In this case we can see that content readability is the most influential factor. Because this is data driven, we can see this is not generalisable best practice to all industries and markets. But it is actionable and will drive rank improvement.
Clustering keywords
Clustering keywords is achieved by comparing the search results between two keywords. If the search results are similar then are deemed to have the same search intent and should therefore be mapped to the same content page.
The data driven part is finding the math to automate this at scale. This is achieved by:
- Reducing the search results for a keyword to a string
- Using a string similarity algorithm to compare the search results
- Grouping the keyword search results according to a threshold (say 60%) similarity for similar search intent
The chart below visualizes keywords that share the same search intent.
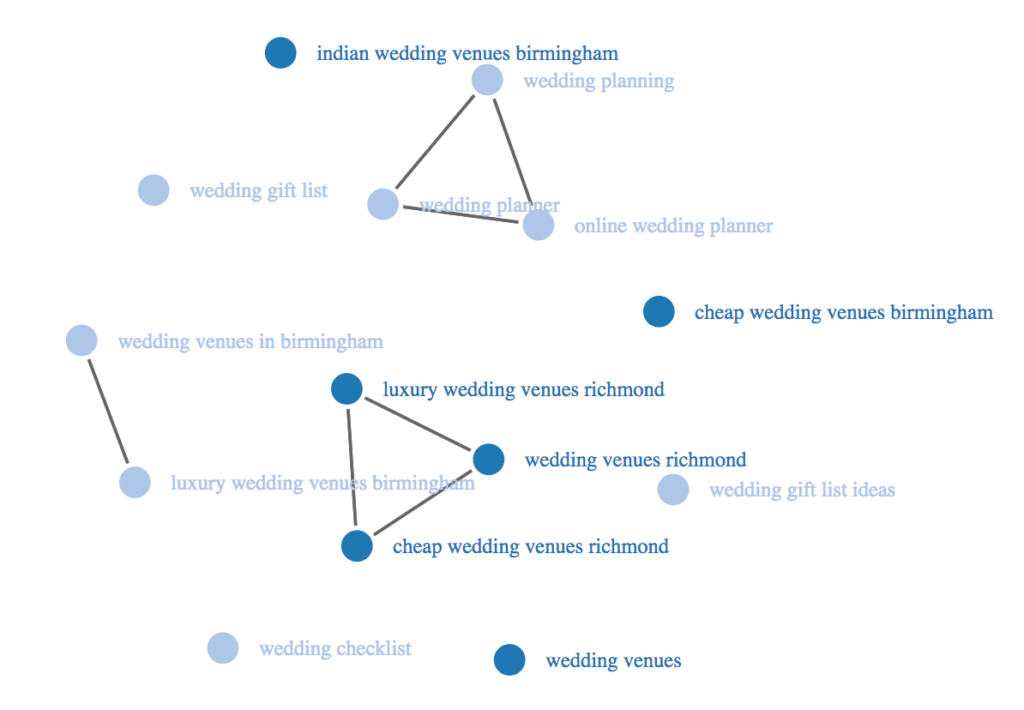
Keywords that share the same search intent are joined by a straight line (called an edge), which informs SEOs on making better decisions.
Split A/B testing
Rolling out SEO recommendations can have a high impact on revenue and therefore become quite high risk if it goes wrong. One way to mitigate against this risk is to Split AB test the recommendation on a group of pages and see whether it improves organic performance (or not) before deciding on whether to roll this out sitewide (or not).
The steps involved are:
- Experiment design to decide on the minimum sample size and the distribution of the data
- Running the experiment
- Evaluating the experiment data to judge whether a significant difference occurred
Naturally, there are platforms such as SearchPilot, that help do all of this for you. However, knowing the math and the python is also an option.
Forecasting traffic
What most, if not all, digital marketing managers and directors want to know is how much organic traffic will the website generate in the future (usually this year).
SEO experts can answer this question by using time series forecasting techniques which look for patterns in time series data, which would be organic traffic over a series of dates. The forecasting techniques achieve this by deconstructing the data in terms of:
- Seasonality – the repetitive nature and how cyclical it is (daily, monthly, weekly etc)
- Trend – the general direction
- Auto-correlation – the impact of the previous data point
The time series models analyze the data in terms of the above features which remove the noise and thus makes it more predictable. The only downside is that you require lots of data to make a reliable forecast!
Other SEO applications
Here are some other ways statistical techniques can be applied in SEO:
- Keyword research – finding the keywords that will generate the most performance and should therefore be targeted (distribution analysis is your friend).
- Simulating PageRank – the benefit of making technical changes to your website to your targeted pages.
- Core web vitals (CWV) – estimating the ranking benefit of improving CWV in your market sector (regression).
- Internal link – optimising the search engine paths to your website content (distribution analysis)
- Algorithm updates – understanding the changes Google is rewarding post update and which pages gained/lost performance (regression)
- Content gaps – finding content that Google expects of your brand (set theory)
- PR Ideation – using data to create ideas based on content that generates the most links over time (distribution and regression)
- Performance reporting – distilling and displaying various aspects of SEO performance with a view to knowing, understanding and responding to the SEO data of the website (statistical aggregation).
The above list isn’t exhaustive and the SEO imagination is the limit. So…
What are the main sources of data for SEO?
Data driven obviously requires data of which the main sources are:
- Google Analytics – 1st party data on your website such as traffic, engagement and revenue dimensionalized by user demographic, device, content, traffic sources and other
- Google Search Console (GSC) – Also 1st party data on organic performance in terms of impressions, traffic, SERPs click through rates and Google rank position by page, device, keywords, country and other
- Keyword research tools – 3rd party data from Similar Web, SEMRush and Ahrefs showing keywords and their search traffic potential. These are mostly used for competitor analysis. Although the data values may not be gospel, they will be consistent.
- Backlink tools – Such as Ahrefs, Majestic and Moz show where sites are getting their traffic from and which content generates links
- Social media – Platform tools such as buzzsumo can be used to estimate which social media influencer content generates the most traffic and engagement to help understand and create effective content
- Crawling tools: Such as Screaming Frog, Botify, Sitebulb (our favorite) help identify technical SEO issues such as broken links which can feed into a competitor analysis for example. Web scraping using Python libraries like BeautifulSoup, Scrapy, and Selenium, is also an option.
Resources to make SEO become more data driven
There are a number of options to make the SEO process more data-driven:
- Books – Currently there is only 1 book available on data driven SEO by Andreas Voniatis (me) which is published by Springer APress
- Learn Python – Python is essential for data extraction (such as working with APIs, web scraping), analysis and science (using Pandas, NumPy and SciPy among other libraries), and automation of repetitive tasks. Try this free Python course from Udacity
- Learn math and statistics – Your Python will only be as good as your math! So it makes sense to learn math and stats to identify trends and patterns in SEO data leading to higher impact recommendations. A good starting point is the free statistics course (again) from Udacity
- Learn data science – Your Python will only be as good as your data science also! Data science will help you combine and scale your math and Python skills to solve SEO challenges. It will also give you the mindset on how to approach SEO in a data driven manner.
- Follow the SEO Pythonistas – The website which honors the late Hamlet Batista features fellow leading voices and their work on data driven SEO such as JC Chouinard and Charlie Wargnier
Make your SEO Data-Driven
Now that you know what data driven SEO is and how it helps your business brand grow, let’s chat and explore how we can help you scale.