
According to SEO statistics, 6.7% of 1,601,261 SEO professional online responses worldwide (source: X, Reddit, Quora and TikTok, 2024) focus mostly on SEO site audits.
We explain how to conduct a technical SEO audit with code by way of
- What is a technical site audit?
- Crawl your site
- Join your data sources
- Segment
- Statistical analysis
- Crawlability and Indexability
- User Experience (UX)
- Recommendations
- Next level
What is a technical site audit
A technical site audit examines the search engine experience of interacting with your website which models the search engine capability of:
- Discovery: Finding the content (Crawling)
- Interpretability: Understand the content (Rendering)
- Worthiness: Content value for search engine result inclusion (Indexing)
- Importance: Estimate the relative importance of the site content relative to other pages within the same website. To understand the content’s importance relative to other content on the internet, search engines will overlay backlink information to determine URL level authority (Google’s proprietary measure is called PageRank).
The website audit achieves this by simulating the behavior of a search engine (Google, Bing, Yandex, Baidu, DuckDuckGo) interaction with a website. This is in order to anticipate the impact of the website on a search engine capability to crawl, render, index and rank.
Crawl your site
2 software modes exist for SEOs and webmasters to crawl websites and get date to simulate search engine website interaction:
Desktop: The software is run locally from a laptop or desktop computer from brands such as ScreamingFrog, Sitebulb. These are often financially cheaper but limited to the capacity of the device running the crawl.
Cloud: Operates from the cloud allowing for crawls of multiple websites in parallel. While more expensive, these crawls are more suited to large websites in the context of Enterprise SEO. Leading brands include Oncrawl, Botify, and Lumar.
To run a website crawl: select your software, create a project, input the site parameters including the website start URL and initiate the crawl.
Join your data sources
Add data from sources such as:
- Traffic: Google Analytics
- Search Engine Performance: Google Search Console
- Backlinks: AHREFs, SEMRush
Additional context and information to better understand the crawl data will be made easier using the above data sources such as high value orphaned pages that should integrated into the crawlable site architecture.
This data join can be done before the crawl in the crawler software tool or merged separately to the post crawl data.
Segment
Segmenting the URLs by crawl type adds more insight to the data helping SEOs understand any technical issues by content type, which accelerates the resolution of that issue quicker and more accurately.
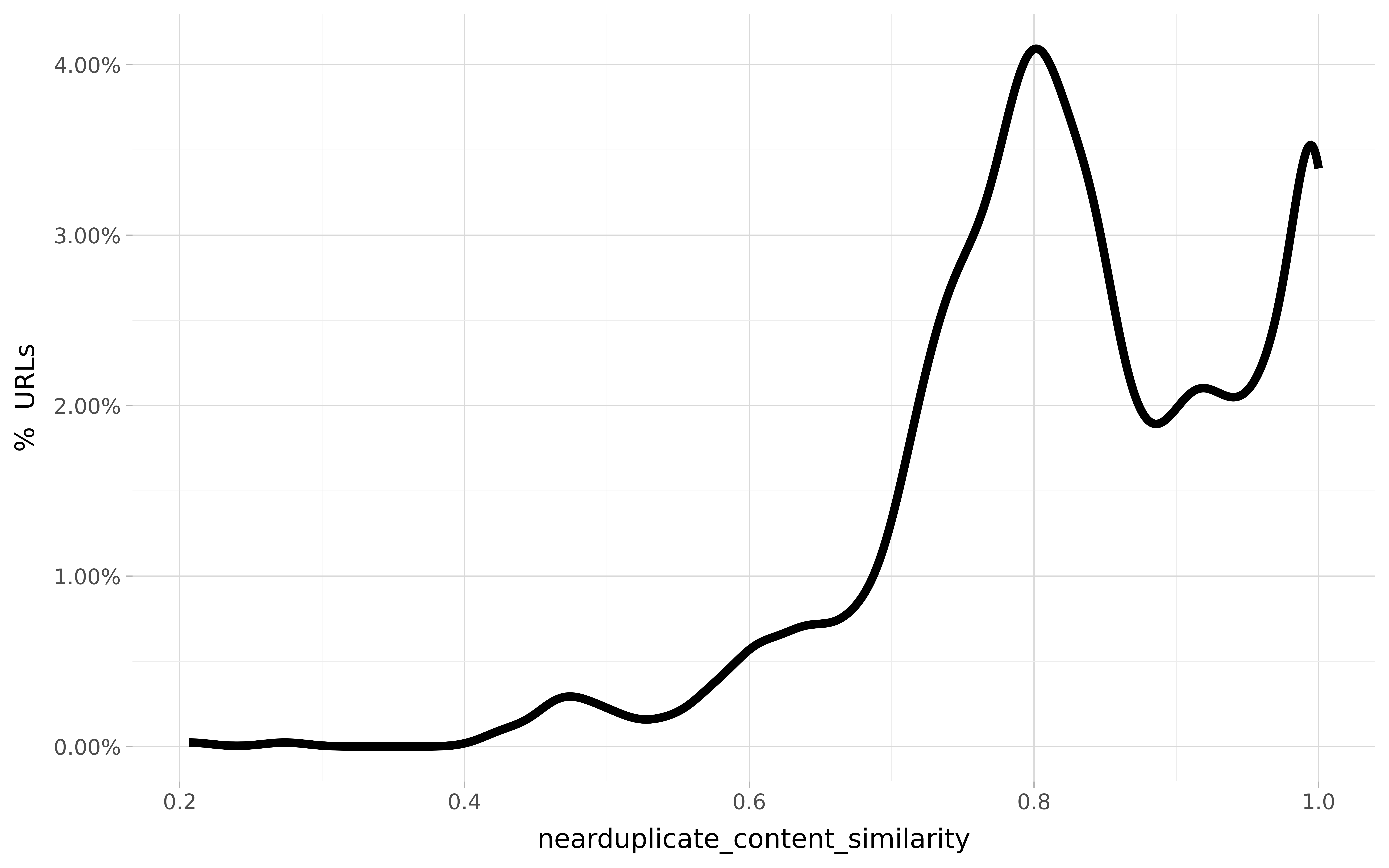
For example, the chart below shows the distribution of duplicate similarity scores by content type:

The Python code to achieve content segmentation of URLs uses np.where() function as shown below:
crawl_segmented['content'] = np.where(crawl_segmented['url'].str.contains('product'), 'pdp', crawl_segmented['content'])
Some cloud crawling software such as Oncrawl already provide this feature natively.
Statistical analysis
Use statistical analysis to avoid making imprecise recommendations. Plotting distributions for each of your technical issues or features increases SEO understanding of how prevalent and widespread the issue is in the website.
Audit Crawlability and Indexability
Search engines process the website on the internet in this order:
- Crawling: Discovering and accessing URLs through HTML hyperlinks. The HTML, CSS, JavaScript and other resource code is extracted from the URL document.
- Rendering: The code is executed to recreate the experience that is presented to website visitors. This helps search engines estimate the user experience (UX) quality of the web page. The code is rendered either server-side (the web server hosting the website) or client side (the web browser visiting the site).
- Indexing: The rendered content is interpreted and evaluated for whether the URL will (or not) be included in the search engine database.
Decide which pages should be open to Search Engines
Crawl software lists feature data for URLs and assumes they have technical SEO issues that prevent them from being made indexable.
However, crawl software doesn’t know if URLs are intended to be excluded, so not the volume of technical issues reported are almost always higher than the true amount.
Thus SEO professionals will have to perform additional filtering to the data before making recommendations.
There are 6 main areas in Technical SEO auditing that determine the fitness of URLs for search engine indexing:
Robots.txt
Robots.txt is a text file document located in the root folder of the web server which instructs search engines by their bot names, as to which URLs and subdirectories they may crawl and not crawl.
Robots.txt files also list the XML sitemap URL.
An example of robots.txt content is shown below:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://yourwebsite.com/sitemap.xml User-agent: Rogerbot User-agent: Exabot User-agent: MJ12bot User-agent: Dotbot User-agent: Gigabot User-agent: AhrefsBot User-agent: SemrushBot User-agent: SemrushBot-SA Disallow: /
Analyzing robots.txt helps SEOs determine whether it’s configured correctly for search engines to access intended URLs or not.
Correct configuration in robots.txt prevents search engines wasting their crawl budget on unnecessary dynamic URLs.
Sitemaps
Sitemaps list the URLs intended for both crawling and indexing by search engines.
This can be in both XML and HTML format.
The XML format is declared in the webmaster console (Google Search Console and Bing Webmasters for example) and in the robots.txt file.
SEO professionals analyze the sitemap to check if it’s updated to include all the intended URLs.
Robots Tags and NoIndex
Robots tags direct search engines on the following main functions:
- Index/Nonindex: Indicate inclusion or non inclusion of the URL in the search engine index
- Follow/Nofollow: Indicate accessing of hyperlink of URLs found
The meta robots tag is inserted inside the </head> section of the HTML web page and takes the form:
<meta name="robots" content="noindex, nofollow"/>
SEOs analyse these to check for URLs that should or shouldn’t be made available to search engines and also for conflicts.
Canonical Tags
Canonical tags let search engines know the preferred URL version of content, which is useful to consolidate authority (aka link equity). This HTML tag is also located inside the </head> section of the HTML web page:
<link rel="canonical" href="https://yourwebsite.com/some-url" />
Canonical tags detailed in the technical SEO audit help SEOs analyze the extent to which the site is configured to maximize the rank position potential of its web pages.
HTTP Status codes
HTTP status codes represent web server feedback which tells search engines whether URL content is live (200), redirected (301, 302, 307, 308), retired (404, 410) or simply unavailable (502, 503, 504, 505).
SEO auditing tools report status codes to help SEOs maximize live (200) URL volumes while minimizing the number of non-200 URL instances. Additional reporting is used to help SEOs determine the cause of the non-200 URL statuses for accurate resolution.
Duplicate content
Duplicate content are instances of content being duplicated across multiple URLs. Duplicate content has multiple causes including URL parameters, CMS template design, too few words being used and so forth.
Duplicate content presents issues to search engines as it is non-value adding for a search engine index to include multiple versions of the same content that target the same keyword. Therefore, SEOs seek to minimise instances of duplicate content.
Orphan URLs
Orphan URLs are URLs without a parent node and as such cannot be found on the HTML crawl map. The SEO impact of orphan URLs is that their authority and their rank position potential are minimized.
However, not all orphan URLs are necessarily an issue as some of these will be purposed for paid search landing pages for example.
SEOs will analyze orphan URLs for potential reintegration into the HTML site architecture.
Site Architecture and internal links
The site architecture concerns the order in which content is configured for discovery within the website starting from the home page. The proximity of the content to the home page signals higher importance to search engines due to being more easily discovered by users.
Content is interconnected and made more discoverable by internal links and its text labels (known as anchor text).
SEOs evaluate the website architecture effectiveness by analyzing the internal link structure and anchor text.
Schema Tags
Schema tags were created by a consortium led by Google, Microsoft and Yahoo! to give additional context of web content to search engines.
SEOs use technical audits to search for malformed schema tags implemented and for missed opportunities of schema not yet deployed.
User Experience (UX)
Although search engines aren’t users, they attempt to estimate the experience delivery to website visitors.
Naturally, a UX friendly website is highly correlated with a search engine friendly website, which translates to better SEO in the form of higher rank positions and user search traffic.
Speed
Website URL browser loading speeds affect the UX, site conversion rates and the search engine render processing cost.
The higher the web page speeds, the better the UX and the lower the search engine cost of processing.
In 2010 Google announced that page speed is a ranking factor for desktop searches.
In July 2018, Google further announced page speed is a ranking factor for mobile searches.
SEOs rely on Google’s proprietary metric known as Core Web Vitals (CWV) to measure, diagnose and improve slower web pages.
Mobile Friendliness
According to StatCounter, over 62% of internet traffic is on mobile phone devices. In 2015, Google announced mobile friendliness would be a ranking factor as part of the Mobile-Friendly Update dubbed as Mobilegeddon.
Technical audits highlight URLs and their templates that are not mobile friendly.
However with modern content management systems (CMS) such as WordPress and Webflow, most websites are mobile responsive.
Accessibility
In 2022, John Mueller averred in the Google Search Central YouTube channel that accessibility indirectly impacts rank positions in Google.
Web Content Accessibility Guidelines (WCAG) Guidelines were introduced in 1995 by W3C to improve accessibility of web content on the internet. The latest version is WCAG 3.0.
WCAG is the reference relied upon by the US law Americans with Disabilities Act (ADA).
WCAG guidelines work on the following principles known as POUR:
Perceivable: Users can perceive digital information mainly by sight, hearing and touch without challenges.
Operable: Website is easy to interact, to navigate and operate.
Understandable: Websites use clear language and intuitive helping users avoid mistakes.
Robust: Content must be reliable across multiple technologies or digital platforms and adaptable to various accessibility tools. Examples include using proper markup language formatting, unique ID attributes, etc.
SEO website crawling software such as Sitebulb audits website user accessibility, however according to Artios data responses, only 4.2% of 110,055 SEO professionals worldwide feature WCAG compliance in the technical site audits.
Headings and Page Layout HTML Content Markup Tags
HTML tags such as headings (h tags like h1, h2) help search engines and users understand the main topic theme along with their breakdown.
SEOs use these tags to ensure the URL content signals clearly to search engines the topic so that search engines easily determine the search queries being targeted and the URLs should rank for.
Headings and Page Layout HTML Content Markup Tags are used for on-page optimisation.
Word Count and Readability
Site audit software also gives information on word counts per URL, the reading ease of the words.
While there is no agreed best practice on the optimum amount of in-body content number of words as the search intent varies from blog post to a product item page, SEO audits seek to ensure each content type meets a minimum word count to avoid near similar content.
Traffic and Log file analysis
Content that receives zero traffic is an issue because it’s perceived as having no value by search engines.
Advanced SEOs join traffic and search analytics data to URLs to check for URLs not receiving traffic.
Log file analysis takes this further by showing actual search engine visits to URLs which can aid SEO decisions on whether content should be retired or redirected.
Recommendations
SEO technical audit recommendations are labeled by:
- Priority
- Commercial impact
- Ease of implementation
Next level
In SEO, everything is relative to the competition so for our next article on technical SEO audits we cover the data science of modeling competitor technical features with organic search performance.